jap:
hibernate:
ddl-auto: noneJPA를 이용해 만들어두었던 User Class와 Table을 Mapping해 보겠다.
이전에 만들어 두었던 User객체를 활용할 것이다. 이 User객체를 살펴보면 두가지 필드가 있다. 이름과 나이인데
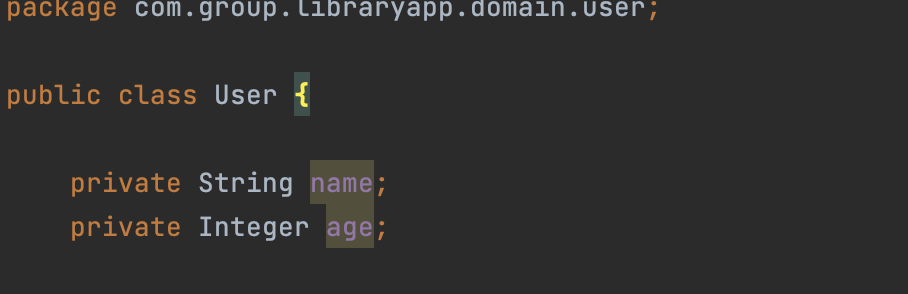
객체에는 name과 age가 있고 내가 만든 Table에는 id와 name, age가 있다. 이를 Mapping해보겠다.
가장 먼저 해줄 것은 UserClass에 Entity를 어노테이션해주는 것이다.
이 Entity의 쓰임새는 스프링이 User객체와 user테이블을 같은 것으로 바라본다는 의미이다. 또 Entity 단어의 의미는 데이터베이스 쪽에서 저장되고, 관리되어야 하는 데이터를 의미한다.
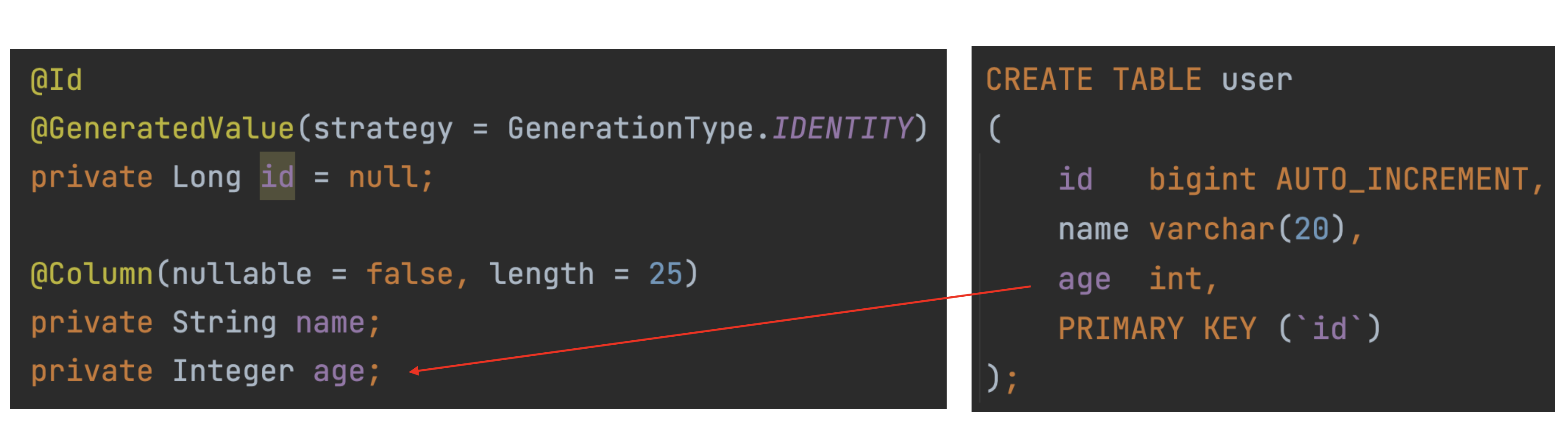
그 다음으로는 User 테이블에는 있지만 UserClass에는 없는 id를 추가해주어야 한다.
이 때 id를 추가할때는 어노테이션을 사용해주어야한다.@Id 어노테이션과 @GeneratedValue
그리고 user 테이블에서는 id의 데이터타입을 bigint로 만들었는데 자바에서는 Long을 사용해주면 된다.



@GeneratedValue를 왜 사용할까?
Table을 만들당시 id에 auto increment를 사용했기에 strategy = GenerationType.IDENTITY를 붙여준것이다.
@id 어노테이션은 이 필드를 primary key로간주한다는 뜻이고,
@GeneratedValue는 primary key를 자동 생성되는 값.
strategy = GenerationType.IDENTITY 에 있는 Identity는 MySQL의 auto increment와 동일하다.
왜 Identity를 사용하냐면 DB종류마다 자동 생성전략이 다르기에 지금사용하고 있는 MySQL를 대응하기 위해 JPA에서 제공하는 GeneartionType에서 Identity를 사용하는 것이다.
MySQL은 auto increment를 사용하니 그에 맞는 GenerationType의 Identity를 사용하는 것이다.
그리고 추가해 주어야 할 것이있다. JPA객체 즉 Entity객체에는 매개변수가 하나도 없는 기본 생성자가 꼭 필요하기 때문에 기본생성자를 생성해주어야한다.
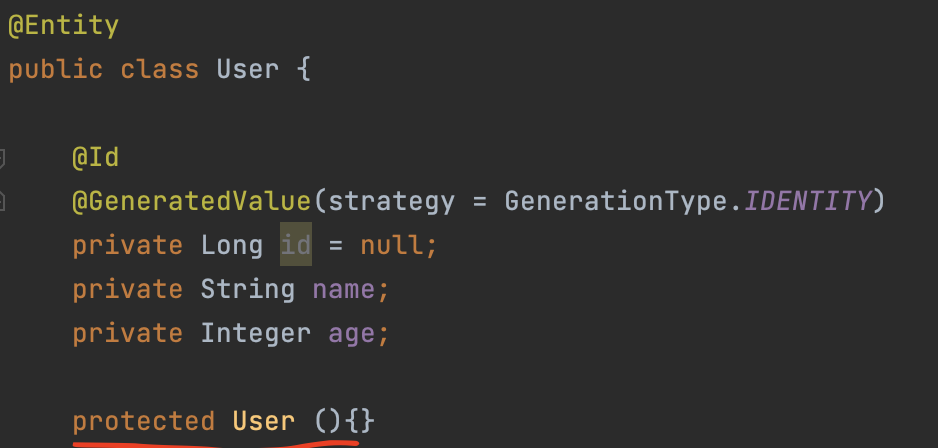
이제 id 까지 mapping해주었으니 id가 아닌 기본 column을 매핑해 줄것있다. name 등등 이 때 사용하는 JPA어노테이션은
@Column이다.
이 어노테이션은 객체의 필드와 Table의 필드를 매칭해준다.

설명해보자면
@Column어노테이션을 작성해준 후에
이름은 null이 들어갈수 없으니 nullable = false, 최대 20자로 설정했으니 length는 20, name은 MySQL의 "name"이라는 뜻이다.
위처럼 @Column 어노테이션 작성 후에는 Table을 만들 당시 설정한 내용들 즉 null이 들어갈 수 있는지 여부, 길이 제한, DB에서의 clumn이름등이 같은지 등을 적어주면된다. 위처럼 User Class name과 User Table의 name이 같으면 생략도 가능하다.
@Column뒤에 조건들은 상황에 따라 생략도 가능하다.
age 처럼 딱히 조건도 없고 특이사항이 없으면 생략도 가능하다.
package com.group.libraryapp.domain.user;
import javax.persistence.*;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id = null;
@Column(nullable = false, length = 20, name = "name") //name varchar(20)
private String name;
private Integer age;
protected User (){}
public User(String name, Integer age) {
if(name == null || name.isBlank()){
throw new IllegalArgumentException(String.format("잘못된 name(%s)이 들어왔습니다", name));
}
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
}이렇게 하면 User Class와 User Table의 Mapping은 끝이 났다.
단 JPA를 사용하니 추가적인 설정을 해주어야 한다.
이 강의를 듣기 시작할 때 데이터베이스를 연결하기 위한 설정을 했었는데 application.yml에서 설정을 추가해 주면 된다.

위에 있는 코드들의 옵션들이 어떤 의미들인지 하나하나씩 알아보겠다.
jpa:
hibernate:
ddl-auto: none이 부분의 의미는 스프링이 시작할 때 DB에 있는 테이블을 어떻게 처리할지에 관한 내용이다.
객체랑 테이블이랑 Mapping을 했는데 Mapping한 테이블이랑 객체랑 조건이 다르다? 하는 경우를 이를 검증을 해봐야 하는데 이런 다양한 상황에 대해서 스프링이 시작할 때 DB와 객체가 다를 때 어떻게 처리할까? 하는 부분이다.
예를 들어서
none 말고 다른 것도 있다.
| create | 기존 테이블이 있다면 삭제 후 다시 생성 |
| create_drop | 스프링이 종료될 때 테이블을 모두 제거 |
| update | 객체와 테이블이 다른 부분만 변경 |
| validate | 객체와 테이블이 동일한지 확인 |
| none | 별다른 조치를 하지 않는다 |
위 코드에서 MySQL설치도 잘했고 Table도 똑같이 만들어 주었기 때문에 none을 사용했다.
properties:
format_sql: true
show_sql: true
dialect: org.hibernate.dialect.MySQL8Dialect그 다음 코드를 살펴보자면
show_sql 은 JPA를 사용해 DB에 SQL을 보낼 때 SQL을 보여줄 것인가?
format_sql 은 SQL을 보여줄 때 예쁘게 포맷팅해서 보여줄 것인가? 하는 의미이다.
dialect는 한국말로 해석하자면 방언, 사투리라는 의미인데 이 옵션으로 DB를 특정하면 조금씩 다른 SQL을 수정해준다.
여기까지 객체와 Table을 Mapping해보았다.
다음에는 DB에서 설정하지 않고 DB에 데이터를 추가해보도록하겠다.!
'기록해보기' 카테고리의 다른 글
| Spring Data JPA를 이용해 다양한 쿼리 작성하기 (0) | 2023.06.18 |
|---|---|
| Spring Data JPA를 이용해 자동으로 쿼리 날리기 (1) | 2023.06.11 |
| 문자열 SQL을 직접 사용하는 것이 너무 어렵다!! (0) | 2023.06.11 |
| 3번째 정리! (0) | 2023.06.11 |
| 스프링 컨테이너를 다루는 방법 (0) | 2023.06.07 |




댓글